
 个人主页
个人主页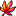 Debug Blog
Debug Blog

记一次抓取全国水雨情信息
现有一需求,抓取全国水雨情信息网站上的大江大河实时水情,结果在过程中遇到了一些坑,便打算记下来,另外趁此机会记录下整个过程供自己和大家参考。
观察网站
这个网站一打开不在大江大河页面,切换是用JS控制的,由此可推断数据肯定是用AJAX方式得到的。因此直接从该链接抓取HTML是不可行的,必须找到它数据传输的接口。
需要注意的是,这个网站在数据部分无法右键,估计是写挫了。如果我们想审查元素的话,可以按F12再点击审查元素界面左上角的箭头按钮,也可以直接按Ctrl+Shift+C。之后再移动到页面上想审查元素的位置即可。(Chrome浏览器)
查看JS
审查元素打开Sources页面观察JS代码,发现该网站使用了一个名为DWR的库。读一下ssindex.js,发现获取数据使用的是IndexDwr.getSreachData函数(这里吐槽一下连单词都拼不对)。再看IndexDwr.js,发现该函数实际上是dwr.engine._execute传入getSreachData参数。
网站引用了一个engine.js,一看就是DWR相关库函数。读一读这个文件里的函数名,最终发现获取接口的函数名为dwr.engine._constructRequest。
调试JS
依然在Sources页面,打开engine.js,在dwr.engine._constructRequest函数最后一行return request;处点击行号增加断点,再刷新页面,JS代码就会执行至此然后暂停。读这段JS发现我们要找的接口地址就是request.url,需要给的信息(以GET或POST方式发送)就是request.body。接着,进入Console页面,输入request.url和request.body,得到接口信息。
不过当时我是几乎把JS代码全看了一遍,才找到这个位置,后来发现应该直接搜索new XMLHttpRequest();,找到新建请求的变量,跟踪该变量即可。
测试接口
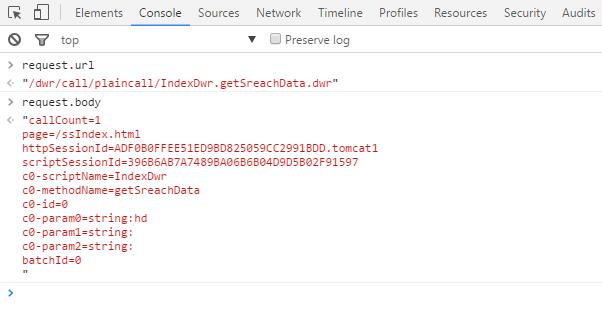
现在得到了接口,下面就是要测试接口了。其实我们还差一个信息,那就是接口是用GET还是用POST呢?我在查看函数时发现了"GET"字样,就天真的以为请求方式是GET了。于是把参数放到URL最后,即以&key=value这种GET形式直接访问,但是获取不到数据。改用POST才可以。后来才发现该函数里有个变量batch.httpMethod,在控制台中输出就可以看到请求方式是GET还是POST。
另外其实有种可以不看代码的方法,就是查看接口地址的HTTP Header,即在Network中找到接口地址(IndexDwr.getSreachData.dwr),查看Request Method。
而我们没有办法直接提交POST信息,因此我借助了一个扩展程序:Postman - REST Client,将地址和需要POST的数据填入,再提交即可。至此,成功获取数据!
初步处理
使用PHP+curl来抓取数据。不过需要注意一下,这个网站是GBK编码的,所以抓取后需要转换成UTF-8以便后续处理。
观察得到的数据,发现数据是HTML形式的,但是是以类似JS字符串形式存放的。接下来就是要处理它,把它变成HTML,以供后续处理。
如果是用JS来写后端的话,这事就简单了,直接读一下就会去掉转义以及\uXXXX形式的Unicode字符。但是关键在于我是用PHP写的(后端我也只会PHP),事情就有些麻烦。
考虑到PHP中有json_decode函数,可以解析JSON,而且不一定非要JSON标准格式,用双引号括起来的字符串就可以,因此非常类似于JS字符串。
但是在这里我遇到了个坑,就是JSON中的单引号不需要转义,也必须不能转义,否则无法解析。
了解到以上几点以后,我们就可以找到解决问题的方法,即先把\'都替换成',再进行json_decode。也就是:
$data=str_replace('\\\'',"'",$data);
$data=json_decode($data);
后续处理
此步骤主要就是处理HTML得到我们所需要的数据了。处理HTML的库我只用过simple_html_dom.php,所以这次也用它来处理。
其实数据很简单,就是一个表格,简单处理一下每个tr中的每个td,每次把一个tr里的数据插入到数据库里即可。
但是这里要注意几个问题:
网站数据是不断更新的,抓取是要隔一段时间抓一次的,所以会有很多表格,怎么存数据库是需要考虑的问题。因此将站点标识与时间一起作为主键,这样就不会有数据丢失了,且便于索引。
观察数据后发现,不用流域可能有相同的站名,所以将站名作为站点标识不可取。但是如果把流域、行政区等信息一起作为主键,这样效率就太低了,而且还存在这些信息全完一样的不同站点信息,所以不可取。不过我发现站名的onmouseover属性中,写了该站点唯一的代号,因此选择将该代号作为站点标识。
考虑到爬虫可能要运行超过一年,因此我给日期加上了年份。而且这个年份不能通过系统时间获取,因为在跨年的时候可能会产生问题。而onmouseover属性也有信息的年份,所以直接获取即可。
将水位信息中的表示变化的箭头给单独处理出来,便于以后信息的处理。
去掉其他无用的信息,如
。最好把每次抓取到的数据的HTML保存下来,万一出了问题还能补救。
任务计划
由于网站上的数据的更新时间不固定,因此我想每隔半小时进行一次抓取。在Windows上这事就特别简单,添加个计划任务即可。
在php文件旁边写一个ScheduledTasks.bat,里面内容是I:\xampp\php\php I:\xampp\htdocs\CESS-hydroinfo\main.php(根据自己的相关路径进行修改)
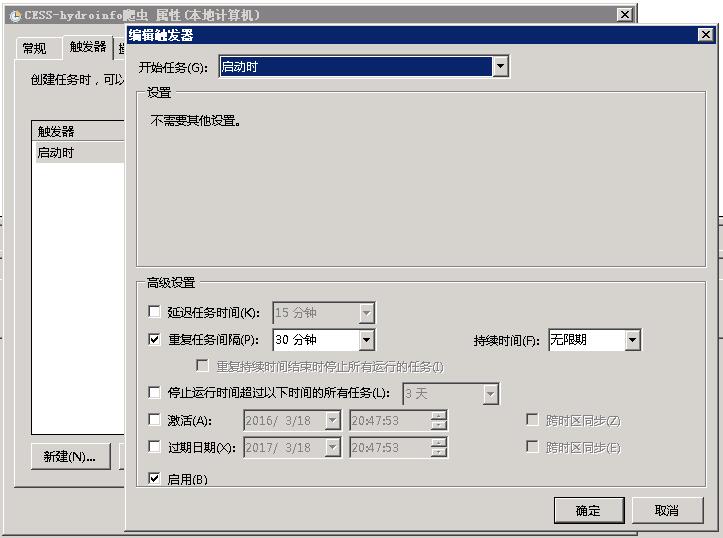
运行taskschd.msc打开任务计划,添加一个在登录前,以最高权限执行的计划任务。触发器为系统启动时,重复任务间隔为半小时,持续时间无限期。而操作当然就是运行该bat啦。
保存后运行该计划任务或重启计算机即可。
主要收获
- 应该通过跟踪新建的XMLHttpRequest变量,得到接口信息。
- 应该通过查看HTTP Header判断请求方式是GET还是POST,省时省力。
- JSON的单引号不需要转义。(我不知道这一点其实是因为我没正儿八经了解过JSON)
- PHJP的strpos函数返回的是复合类型,不可用
if (strpos())判断,因为如果找到了且返回下标0,则也认为是false。PHP还有很多类似的其他函数,用之前一定要仔细读WARNING以及下面的高票评论。
后记
后来,发现了更好的获取数据方法,不仅可以获取当前数据,还能获得历史数据,具体接口是http://xxfb.hydroinfo.gov.cn/svg/svgwait.jsp?gcxClass=1&gcxKind=1&DateL=2016-01-01&DateM=2016-02-01&gcxData=7&site=站点代号。不过实测这里DateM并没有起作用,无论设为多少,获取到的都是直到今天的数据。
获取到的数据格式是在一个svg标签里,以DateL为基准过了x小时的那个时刻的水位和流量信息(这个数据是用本来是提供给svg进行绘图的)。这样一次就可以获取一个站点的所有历史数据。
不过,需要注意的是,这个网站的后端里限定了HEADER中必须有REFERER且值为http://xxfb.hydroinfo.gov.cn/svg/svghtml.html,否则会提示“请按照正确方式访问!”。
我是怎么发现的呢?在这个网站里,鼠标移动到站点名称上面,会显示这个站点的折线图,但是要安装插件且在IE下才能打开。我在IE下打开这个页面,查看了一下JS,就找到了这个地址。但是当我直接以GET方式访问时,后台不给我提供数据。于是我在IE里,查看NETWORK,在里面找到这个地址,查看请求标头,并对参数一个一个测试,发现必须有REFERER才行。
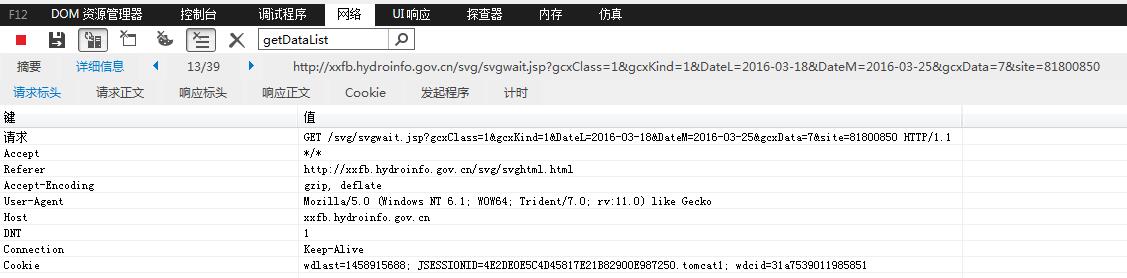
另外,由于这个网站存在COOKIES,因此在抓取时最好把COOKIES一并发过去,如果服务器没有优化的话,每次请求都会让服务器分配新的COOKIES,不久就会耗尽资源。